

By Dorothy Berry
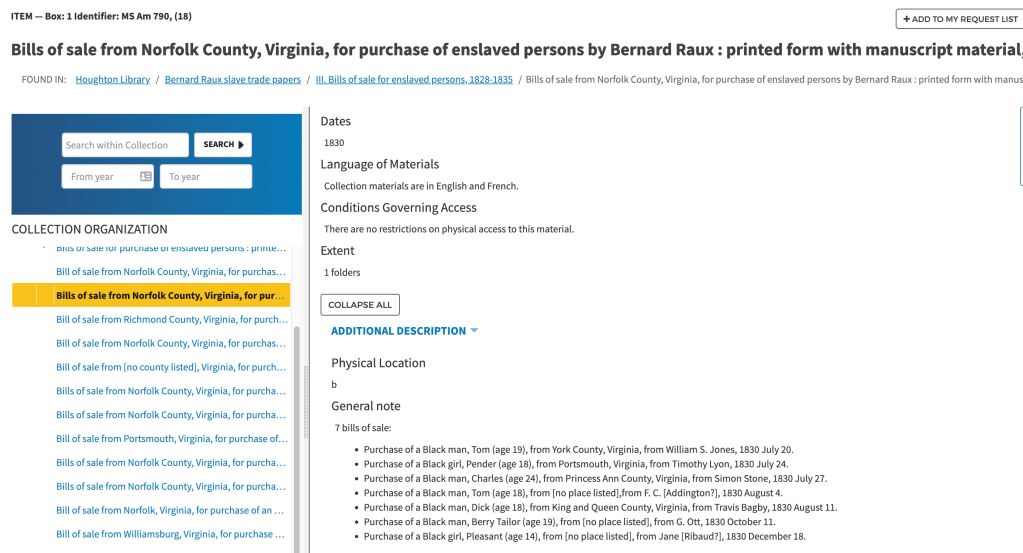
*Image above: An image of the archival object as digital object: multiple bills of sale attesting to the buying and selling of people.
In 2020, Houghton Library, Harvard University’s largest repository for rare books and manuscripts, committed to a year-long focus on building a digital collection featuring materials that illustrate Black life in the Americas from the 18th through early 20th centuries. Managing a big digital project on a short timeline is always a challenge, and even more so when dealing with a remote workforce who are all experiencing the effects of a global pandemic. While the final site, available here, features a variety of interpretative and pedagogical tools for exploring the collection, one of the most innovative for our library’s practices is the interactive dataset that brings materials together across descriptive standards to invite deeper searches.
As a special collections library with an encyclopedic collecting history, Houghton has materials cataloged in MARC records and described in finding aids—both legacy collections described in the manuscript tradition and more recent DACS–compliant discovery tools. To complicate things further, our systems and internal standards do not allow for unique description of digital objects beyond a title change; the digital object is displayed with the descriptive information from its official record, whether that be a detailed catalog record or a very minimal box-level description. While some archival collections did receive clean up, both for clarity and for language that was more respectful to enslaved archival subjects, most of the records weren’t able to receive edited description as the digital project team, (made up of Reference Librarian Micah Hoggatt, Assistant Curator of Modern Books and Manuscripts Christine Jacobson, and Digital Archivist Monique Lassere), didn’t have any staff with official description editing roles.
Working from this context, and with an awareness that many authorized headings did not reflect materials in the way we desired, the project team developed an ad hoc descriptive schema to provide new access points to users. I prepared a spreadsheet using the basic information I had collected around the material I’d curated for digitization- things like call numbers, ArchivesSpace reference IDs, Alma ID numbers, and titles. Next, I laid out the sheet with fields that mirrored DublinCore standards and broke down potential search fields for faceting- things like geographical and temporal information, personal and organizational names. Finally, we had the most interactive/experimental field, what I termed “Theme Tags.” For the length of the project, any team member could add a theme tag to a running list, ranging from content topics to material forms. This field opened up a deeper level of project involvement for our remote team through, sometimes in-depth, virtual conversations about whether a tag needed rephrasing or whether it overlapped too much with other fields or tags.
When the initial phase of the project was completed, and my project team members transitioned back off of this work, I went through the conglomerated “Theme Tags” and broke them down into “Theme Tags,” “Genres,” and “Physical Formats.” Now users who engage with the dataset can search for themes like “Colored Convention Movement,” genres like “Poetry,” and physical formats like “pamphlets.” There are also deeper opportunities to search for individuals, as edited volume contributors who did not make the catalog record and archival subjects who are mentioned in the primary source but not in the folder-level description often did make it into our dataset. Enhancing the metadata, we hope, opens up the possibility for this information to make it appropriately back into our official records through the hands of colleagues who are trained in cataloging and archival description standards.

Above: Before this project, the people named in primary sources—such as the bills of sale shown at the top of this article—were not included in finding aids. We used their listed ages to give them approximate birth years and added them to the data sheet. This work has now fed back into the finding aid, where the description has been updated by one of our archivists to include the names of the enslaved and to change other outdated and/or offensive language (see below).
Developing this dataset was a learning experience for everyone involved and allowed us to consider ways we can provide useful description outside of finding aids and catalog records. The project’s circumstances called for a lot of quick decision making (and a lot of corrections on my end!), but hopefully this process can be replicated in other projects to involve more and new voices in the descriptive process.
Dorothy Berry has spent her career working on the digital discovery of historical documents related to Black life and experiences. She was previously the Digital Collections Program Manager at Houghton Library, Harvard University and is now the first Digital Curator at the National Museum of African American History and Culture in Washington D.C. Her work on archives can be found in up/root, Journal of Critical Digital Librarianship, and JSTOR Daily.
